Redis Deep Dive Part 1: In-Memory Architecture and Event Loop Explained
Published on July 12, 2025
For the past few weeks, I’ve been spending a lot more time working with Redis. This was for a sophisticated circuit breaker implementation that had some custom requirements. To meet those requirements, I had to dig deep into the Redis documentation and ended up learning a lot about Redis internals. I thought sharing those insights could be useful for others, so I’m putting together a six-part series.
This is Part One of that series.
Redis (REmote DIctionary Server) is famous for its blazing-fast performance, often serving millions of requests per second on commodity hardware. This speed isn’t magic; it’s the result of two core architectural decisions: keeping data in memory and using a single-threaded event loop.
Let’s break down how these two pillars work together to make Redis a powerhouse for caching, real-time analytics, and message brokering.
Everything in RAM
The most fundamental reason for Redis’s speed is that it stores the entire dataset in RAM. Unlike disk-based databases like PostgreSQL or MySQL, which have to perform I/O operations to fetch data from an SSD or HDD, Redis accesses data directly from main memory.
The performance difference is staggering. Here’s a rough comparison of data access latencies:
- L1/L2 CPU Cache: ~1-10 nanoseconds
- Main Memory (RAM): ~100 nanoseconds
- NVMe SSD: ~20,000-150,000 nanoseconds (20-150 µs)
- Spinning Disk (HDD): ~2,000,000-10,000,000 nanoseconds (2-10 ms)
As you can see, accessing data from RAM is ~1,000x faster than NVMe SSD, ~100,000x faster than HDD than from any form of disk. A Redis read or write is a direct memory operation, avoiding the massive overhead of disk seeks, I/O scheduling, and page cache management.
This in-memory design also allows Redis to leverage CPU caches effectively. The internal data structures (like hash tables and sorted sets) are optimized to keep “hot” data close to the CPU, minimizing latency even further.
Redis’s in-memory architecture makes it ideal for:
- Session Store (e.g., Uber): Uber uses Redis to store session data for millions of concurrent users, achieving sub-millisecond response times for authentication checks.
- Real-time Analytics (e.g., Twitter): Twitter leverages Redis for counting trending topics, processing millions of tweet interactions per second.
- Gaming Leaderboards (e.g., Zynga): Online games use Redis Sorted Sets to maintain real-time leaderboards for millions of players.
- Rate Limiting (e.g., GitHub): GitHub uses Redis to implement API rate limiting, checking and updating counters for thousands of API requests per second.
Of course, this approach comes with challenges:
- Volatility: RAM is volatile. A power outage or server reboot will wipe out all data unless a persistence strategy is in place. Redis mitigates this with two persistence options: RDB (point-in-time snapshots) and AOF (an append-only log of write operations).
- Data Density and Cost: RAM is significantly more expensive per gigabyte than SSD or HDD storage. This makes storing very large (terabyte-scale) datasets in Redis a costly proposition.
- Capacity Constraint: The size of a Redis dataset is fundamentally limited by the amount of physical RAM available on the server. This necessitates careful capacity planning and often requires horizontal scaling strategies to handle larger datasets.
- Volatility: RAM is volatile storage. Without persistence mechanisms, a server restart or power failure results in total data loss. This forces a trade-off between performance and durability, managed through Redis’s RDB and AOF persistence options. Also, many Redis deployments accept this by persisting asynchronously or treating Redis as a cache of a primary store.
Event Loop
You might think that a multi-threaded architecture would be faster, but Redis relies on a single-threaded event loop for its core operations. This model is based on the Reactor Pattern, which allows a single thread to handle thousands of concurrent client connections efficiently.
Imagine a restaurant with a single, highly efficient waiter. Instead of serving one table from start to finish (and making all other tables wait), the waiter juggles multiple tables:
- Listens: Scans all tables to see who needs attention (e.g., ready to order, needs the bill).
- Reacts: Attends to a table that raised its hand, takes the order, and sends it to the kitchen.
- Loops: While the food is cooking, the waiter immediately moves on to the next table that needs something.
This is exactly how the Redis event loop works. It uses an I/O multiplexing mechanism (like epoll on Linux or kqueue on BSD) to monitor many client sockets at once.
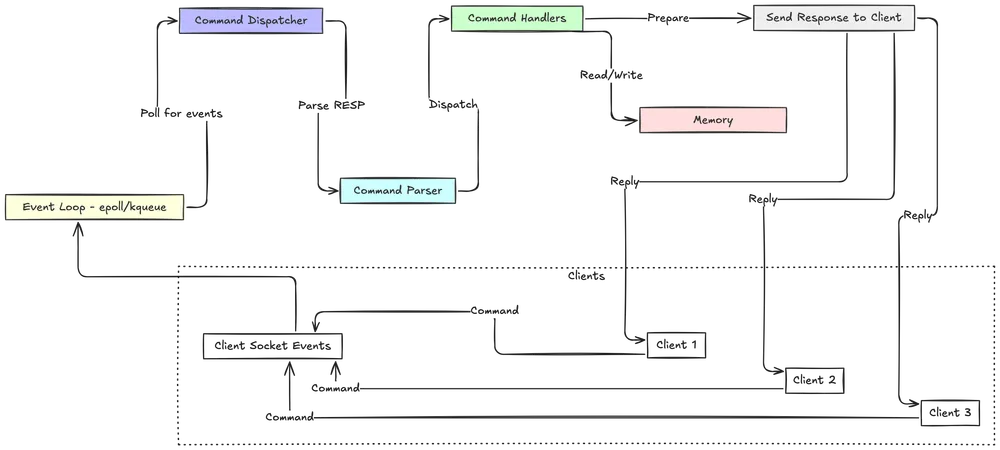
The loop continuously asks the kernel, “Has anything happened on these client connections?” When a client sends a command, the event loop processes it to completion, writes back the reply, and moves to the next event.
The core logic, found in the Redis source file ae.c, is beautifully simple:
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
aeProcessEvents(eventLoop, AE_ALL_EVENTS| AE_CALL_BEFORE_SLEEP| AE_CALL_AFTER_SLEEP);
}
}Redis abstracts these platform-specific APIs in its own event library. At compile time, it selects the most efficient mechanism available on the host system, ensuring optimal performance and portability. The event loop then processes two types of events:
- File Events: These are I/O events from client sockets. When a socket is ready for reading, the loop triggers a handler to read the incoming command. When a socket is ready for writing, it triggers a handler to send the response.
- Time Events: These are tasks scheduled to run at a specific time or interval, such as key expiration checks or other periodic maintenance. They are stored in a linked list and checked on each iteration of the event loop.4
Why Single-Threading Works for Redis:
- No Locking Overhead: With a single thread modifying the data, there’s no need for locks or other synchronization mechanisms. This eliminates the complexity and performance cost of managing concurrent access, making operations like
INCRorLPUSHsafely atomic. - CPU is Rarely the Bottleneck: Redis operations are incredibly fast because they are memory-bound. The server often saturates network or memory bandwidth long before it maxes out a single CPU core.
- Simplicity: The design is simple, predictable, and less prone to concurrency-related bugs.
- Cache locality: The event loop can focus on maximizing I/O and cache locality. It also means the entire CPU core can dedicate cycles to processing data rather than context switching or locking.
The Trade-Offs:
- Single-Core Limitation: A single Redis instance cannot use multiple CPU cores to execute commands. To scale vertically, you must run multiple Redis instances on the same serve
- Long-Running Commands Block Everything: Since the thread is shared, a slow command (like
KEYS *on a large database or a complex Lua script) will block all other clients until it finishes. This is why you should use such commands with extreme caution in production. - No Preemptive Scheduling: Redis cannot preempt a running command mid-way; it will always finish a command before handling new events. In practice this isn’t a big problem because typical commands are fast, but it is a conceptual trade-off.
What about Redis 6.0+ I/O Threads?
Starting with version 6.0, Redis introduced optional I/O threads. This feature does not make command execution multi-threaded. The core principle remains: all commands execute on the main single thread. The I/O threads are used solely to offload the work of reading from and writing to sockets, which can free up the main thread to focus purely on data manipulation, boosting throughput in high-traffic scenarios.
For workloads that need multi-core use within one instance, there are alternatives. Some forks of Redis (like KeyDB) use multithreading.
RESP (REdis Serialization Protocol)
Finally, Redis’s performance is optimized at the network level through its protocol and client features.
RESP is a simple, human-readable, and computationally cheap text-based protocol. Its key performance feature is the use of prefixed lengths for strings and arrays.
- Simple Strings: Prefixed with
+. Used for simple replies like+OK\r\n. - Errors: Prefixed with
-. Used for error messages, e.g.,-ERR unknown command 'foo'\r\n. - Integers: Prefixed with
:. Used for integer replies, e.g.,:1000\r\n. - Bulk Strings: Prefixed with
$. This is used for sending binary-safe strings of a specified length. The prefix is followed by the number of bytes in the string, a CRLF, the string data itself, and a final CRLF. For example,$6\r\nfoobar\r\n. A null value is represented as$-1\r\n. - Arrays: Prefixed with
*. This is used to send a collection of other RESP types. The prefix is followed by the number of elements in the array, a CRLF, and then the RESP-encoded data for each element. A null array is represented as*-1\r\n.
For example, to send the command SET mykey “Hello World”, the client sends:
*3\r\n$3\r\nSET\r\n$5\r\nmykey\r\n$11\r\nHello World\r\nThe *3 and $length prefixes tell the Redis parser exactly how many bytes to read. This avoids slow, character-by-character parsing and allows for extremely fast command processing.
The design of RESP is a key contributor to Redis’s performance:
- Prefixed Lengths: The most critical feature is that Bulk Strings and Arrays are prefixed with their length. This means a parser does not need to scan the data to find a special terminator character (as is necessary with JSON strings) or handle complex escaping. The parser can read the length
Land then issue a single, efficientreadsystem call for exactlyLbytes of data. This makes parsing computationally trivial and extremely fast. - Binary Safety: Because length is explicit, RESP can handle any binary data (like images or serialized objects) as values without corruption.
- Implementation Simplicity: The protocol is simple enough that writing a client parser is a straightforward task in almost any programming language, which has encouraged broad adoption and high-quality client libraries.
It is worth noting that Redis 6 introduced RESP3, a newer version of the protocol that adds more semantic data types, such as Maps, Sets, Doubles, and a formal Push message type. While RESP3 offers richer client-side semantics, RESP2 remains the widely established standard for client-server communication.
Request-Response Model
The standard communication pattern is simple: a client sends a command to the server as a RESP Array of Bulk Strings. The first element of the array is the command name, and subsequent elements are the arguments. The server then replies with a command-specific RESP type.
For example, the command SET mykey “Hello World” would be encoded by the client as:
*3\r\n$3\r\nSET\r\n$5\r\nmykey\r\n$11\r\nHello World\r\nThe server would reply with a Simple String:
+OK\r\nPipelining
Network latency is often a major performance bottleneck. Pipelining is a client-side optimization that dramatically reduces this overhead. Instead of sending one command and waiting for the reply before sending the next, a client can send a batch of commands at once. Redis processes them all and sends all the replies back in a single go.
This eliminates the round-trip time for every command except the first, massively increasing throughput.
$ printf "SET key1 1\r\nSET key2 2\r\nGET key1\r\nGET key2\r\n" | \
redis-cli --pipeWithout Pipelining:
Client -> SET key1 val1 -> Server
Client <- OK <- Server (1 RTT)
Client -> SET key2 val2 -> Server
Client <- OK <- Server (1 RTT)With Pipelining:
Client -> SET key1 val1, SET key2 val2 -> Server
Client <- OK, OK <- Server (1 RTT total)Using a simple pipeline, it’s common to see Redis handle over 1 million requests per second.
Connection Handling and Pooling Strategies
Clients connect to Redis via a standard TCP connection (defaulting to port 6379) or, for co-located processes, a more efficient Unix domain socket. Due to its event-driven I/O model, a single Redis instance can handle tens of thousands of simultaneous client connections.
However, the process of establishing a TCP connection involves a three-way handshake, which introduces latency. For applications that need to make frequent requests to Redis, creating and tearing down a connection for each request is highly inefficient. The established best practice is for the client application to use connection pooling.
A connection pool maintains a set of open, ready-to-use connections to the Redis server. When an application thread needs to send a command, it borrows a connection from the pool, uses it, and then returns it to the pool. This amortizes the cost of connection setup over many requests and is a critical performance optimization.
Tip: When using connection pools, it would be beneficial to set min and max idle connection to the same value.
A caveat is that blocking commands (like BLPOP or a long Lua script) will block that connection’s event handling. If multiple threads multiplex on one socket, they must coordinate blocking calls carefully (Redis Cluster’s “client-side multi-keys” behaviors).
For workloads with high throughput or large values, network bandwidth can become the limiting factor before the CPU does. A single Redis instance can easily saturate a 1 Gbit/s network interface. For demanding production environments, deploying on servers with 10 Gbit/s NICs is a standard practice.
SSL/TLS Implementation and Performance Impact
Redis 6.0 introduced native support for SSL/TLS encryption. However, this comes with a performance trade-off:
- Handshake Latency: The initial TLS handshake adds several network round trips.
- CPU Overhead: All data must be encrypted and decrypted, consuming CPU cycles.
Benchmarks show that enabling TLS can reduce throughput by 30-60%. Therefore, in high-throughput environments, consider terminating TLS at a load balancer or proxy.
Quick Reference: Redis Performance Tips
- Use pipelining for batch operations to reduce network round trips
- Implement connection pooling with min/max idle connections set equal
- Avoid blocking commands (
KEYS *,FLUSHDB, long Lua scripts) in production - Monitor memory usage to prevent swapping to disk
- Use appropriate persistence settings based on your durability requirements
- Deploy on servers with 10 Gbit/s NICs for high-throughput applications
- Consider Unix domain sockets for co-located applications
- Disable TLS for internal traffic within secure networks
- Use Redis Cluster for datasets larger than available RAM
- Benchmark your specific workload using
redis-benchmark
Redis’s incredible speed is a direct result of smart, focused design:
- In-Memory Storage: Eliminates slow disk I/O by keeping all data in RAM.
- Single-Threaded Event Loop: Avoids locking overhead and simplifies the architecture by handling concurrent requests with I/O multiplexing.
- Efficient Network Handling: Uses a simple protocol (RESP) and client-side pipelining to minimize network latency.
By understanding these principles, you can better leverage Redis in your own applications and appreciate the trade-offs that come with its powerful design. In Part 2, we will explore the highly optimized data structures that build on this foundation.